Today, Gemini 3 lands — and suddenly your search results look like mini apps, your IDE has AI agents running missions, and your codebase fits into a single prompt.
Google is calling Gemini 3 its “most intelligent model” so far, built to bring any idea to life with deeper reasoning, multimodal understanding, and real agent-like behavior.
But what does that actually mean if you’re a founder, developer, or just someone trying to ship real products?
Let’s break it down without the hype – with stories, not just specs.
🌟 Quick Snapshot – What’s New With Gemini 3?
If you only take three things away, make it these:
-
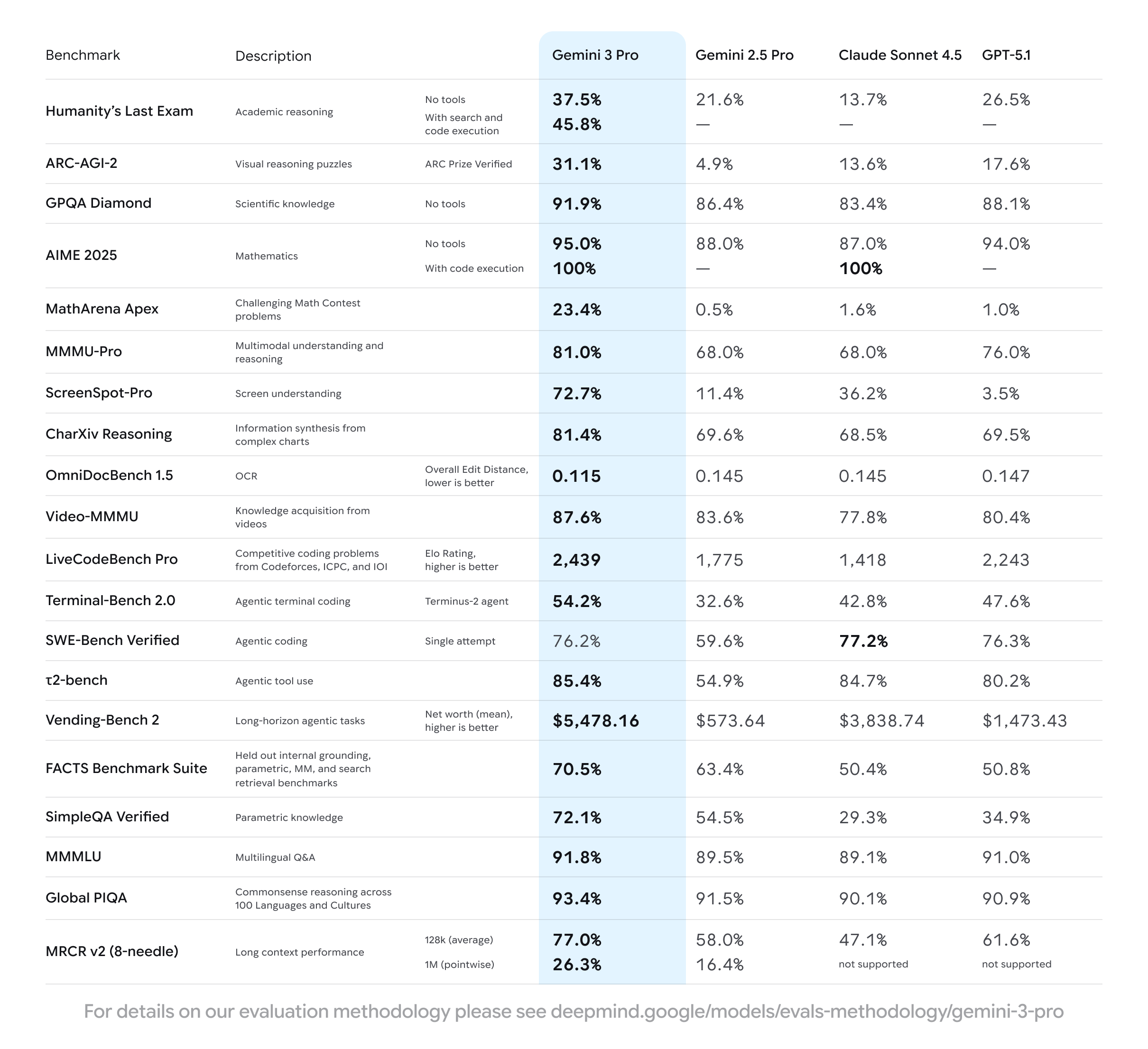
Gemini 3 Pro is the new flagship model — a thinking model designed for complex reasoning, coding, and multimodal work (text, images, audio, video, PDFs, code) with a 1M token context window and 64k output tokens.
-
It powers Google Search’s AI Mode and the Gemini app on day one, with new “generative UI” layouts that look more like interactive dashboards than plain answers.
-
There’s a new Gemini 3 Deep Think mode that pushes reasoning even further, beating Gemini 2.5 Pro on brutal benchmarks like Humanity’s Last Exam and ARC-AGI-2.
In other words: this is not just “Gemini but bigger.” It’s Google’s attempt to move from chatbot to AI teammate.
🤝 Meet the Gemini 3 Family (Today & Soon)
1. Gemini 3 Pro – The Workhorse With a Giant Memory
Gemini 3 Pro (model ID: gemini-3-pro-preview) is the first officially released model in the Gemini 3 line.
Key capabilities:
-
1M token input / 64k output context – big enough to fit:
-
Entire codebases
-
Long research papers
-
Product specs + logs + meeting notes in one shot
-
Deep multimodal – understands text, images, audio, video, PDFs, and code in a single prompt.
-
State-of-the-art reasoning – significantly outperforms Gemini 2.5 Pro on tough reasoning and coding benchmarks, and currently sits at the top of the LMArena leaderboard.
-
Less fluff, more signal – Google explicitly highlights that Gemini 3 Pro is tuned to give direct, non-sycophantic answers — less “you’re so smart, great question!” and more “here’s what’s true, even if it’s not what you wanted to hear.”
You can use Gemini 3 Pro today in:
-
The Gemini app (select the Thinking model)
-
Google Search → AI Mode (rolling out first to AI Pro / Ultra subscribers in the US)
-
Google AI Studio, Gemini API & Vertex AI for builders.
2. Gemini 3 Deep Think – When You Really Need the Brain
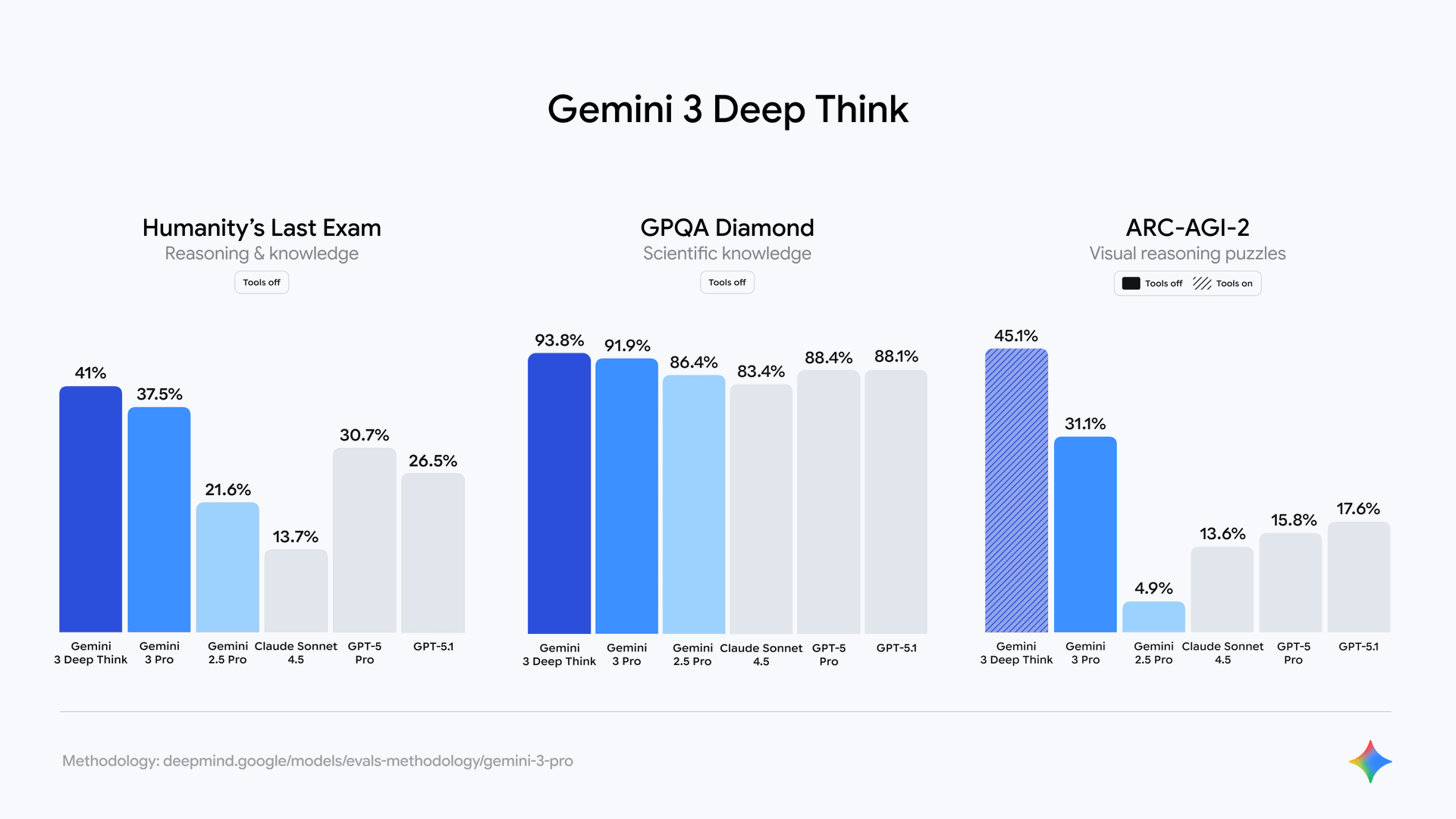
On top of Pro, there’s Gemini 3 Deep Think – a boosted mode designed for extremely hard problems: advanced math, dense research reasoning, long-chain planning.
In Google’s own testing, Deep Think:
- Beats Gemini 3 Pro on Humanity’s Last Exam, GPQA Diamond, and ARC-AGI-2, hitting new highs on reasoning-focused benchmarks.
Right now, Deep Think is rolling out to safety testers and AI Ultra subscribers first, with broader access promised “soon”.
Think of it as:
Gemini 3 Pro = everyday genius
Deep Think = bring this out when you’d normally call three PhDs and block a whole week
3. What About Other Models?
For now, Gemini 3 Pro is the main general-purpose model in this family. Gemini 2.5 variants (Pro, Flash, Flash-Lite) are still around for cheaper, high-throughput workloads, and many teams will run a hybrid stack: 2.5 for “fast & cheap”, 3 Pro for “hard & critical.”
🧠 So What’s Actually Different vs Gemini 2.5 (or GPT / Claude)?
Let’s skip the marketing adjectives and talk upgrades.
1. A Model Built to Think, Not Just Complete Text
Gemini 3 is explicitly described as a “state-of-the-art reasoning” model – not just a bigger text predictor.
-
It uses a sparse Mixture-of-Experts (MoE) architecture, routing parts of your request to different specialist “experts”, which helps it scale to long contexts without blowing up compute costs.
-
On reasoning-heavy benchmarks, it competes directly with GPT-5.1 and Claude Sonnet 4.5, and often wins.
You feel this in practice when you:
-
Ask it to refactor multi-file codebases with tricky edge cases
-
Have it reverse-engineer a complex bug from logs + screenshots
-
Ask for plans that balance constraints (time, budget, tech debt, risk)
It “holds the thread” better over long chains of logic.
2. 1M Token Context That’s Actually Usable
Lots of models brag about big context windows. Gemini 3’s 1M token window is explicitly tuned for:
-
Entire repositories
-
Huge sets of PDFs and documents
-
Long-running conversations and workflows
The real win isn’t just size — it’s how it’s wired for:
-
Agentic coding: ingest legacy systems, generate migration plans, write tests, and execute tasks across tools.
-
Enterprise use: feeding logs, specs, requirements, and code into a single reasoning surface.
You’re not just “asking a model a question” anymore — you’re dropping an entire project on its lap and saying: “Show me the path.”
3. New Controls: Thinking Level & Media Resolution
For devs, there are some very practical knobs:
-
thinking_level – controls how deeply the model reasons:
-
low → faster, cheaper, good for simple chats and CRUD operations
-
high (default) → deeper, slower thinking for hard problems
If you don’t set anything, Gemini 3 Pro uses dynamic high-level thinking by default.
- media_resolution – lets you choose how detailed the model’s vision processing is (low / medium / high) per image/video or globally, so you can balance cost vs accuracy for PDFs, screenshots, and frames.
This is the subtle but important shift:
You’re not just choosing a model – you’re choosing how hard it thinks and how carefully it looks.
4. Search Results That Feel Like Apps
Open Google Search → AI Mode, ask something complex like:
“Create a 3-day workshop plan to upskill my dev team on agentic AI, with resources and exercises.”
Instead of a wall of text, you now get dynamic layouts – cards, images, tables, even interactive simulations — powered by Gemini 3.
Under the hood:
-
Search uses an upgraded query fan-out technique to run more, smarter sub-searches that better match your intent and surface more relevant sources.
-
Gemini 3 is routed to the hardest questions, while lighter models still handle easy stuff so you’re not waiting ages for every query.
This is where “AI model” starts looking like AI browser.
🛠️ How to Try Gemini 3 Today
For Everyday Users
-
Gemini app (web, Android, iOS)
-
Choose the “Thinking” model — that’s Gemini 3 Pro.
-
Google Search → AI Mode
-
Rolling out first to Google AI Pro / Ultra subscribers in the U.S.
You’ll notice:
-
More structured answers
-
Cleaner, less-flattering-but-more-useful tone
-
Rich visual layouts for complex queries
🔗Reference:
https://blog.google/products/gemini/gemini-3/
https://www.theverge.com/news/822833/google-antigravity-ide-coding-agent-gemini-3-pro




