

Industry News
Multicloud Is Back. The Hyperscalers Know It.
AWS Interconnect and Google Cloud Location Finder signal the hyperscalers have conceded multicloud. Here is a pragmatic SaaS reference architecture.
•5 min read
Google made Cross-Cloud Lakehouse on Apache Iceberg GA at Next 26. What cross-cloud caching means for your architecture and your egress bill.

For most of the last decade, "multicloud" meant paying twice — once for the second cloud, and again every time data moved between them. Last week at Google Cloud Next '26, Google quietly took a sledgehammer to the second bill. The cross-cloud lakehouse built on Apache Iceberg went generally available, paired with cross-cloud caching that finally takes the sting out of egress fees on AWS S3 and Azure Data Lake Storage. AWS and Google followed up with a joint multicloud networking announcement in the same week. The cloud control plane has shifted, and most architecture decks haven't caught up yet.
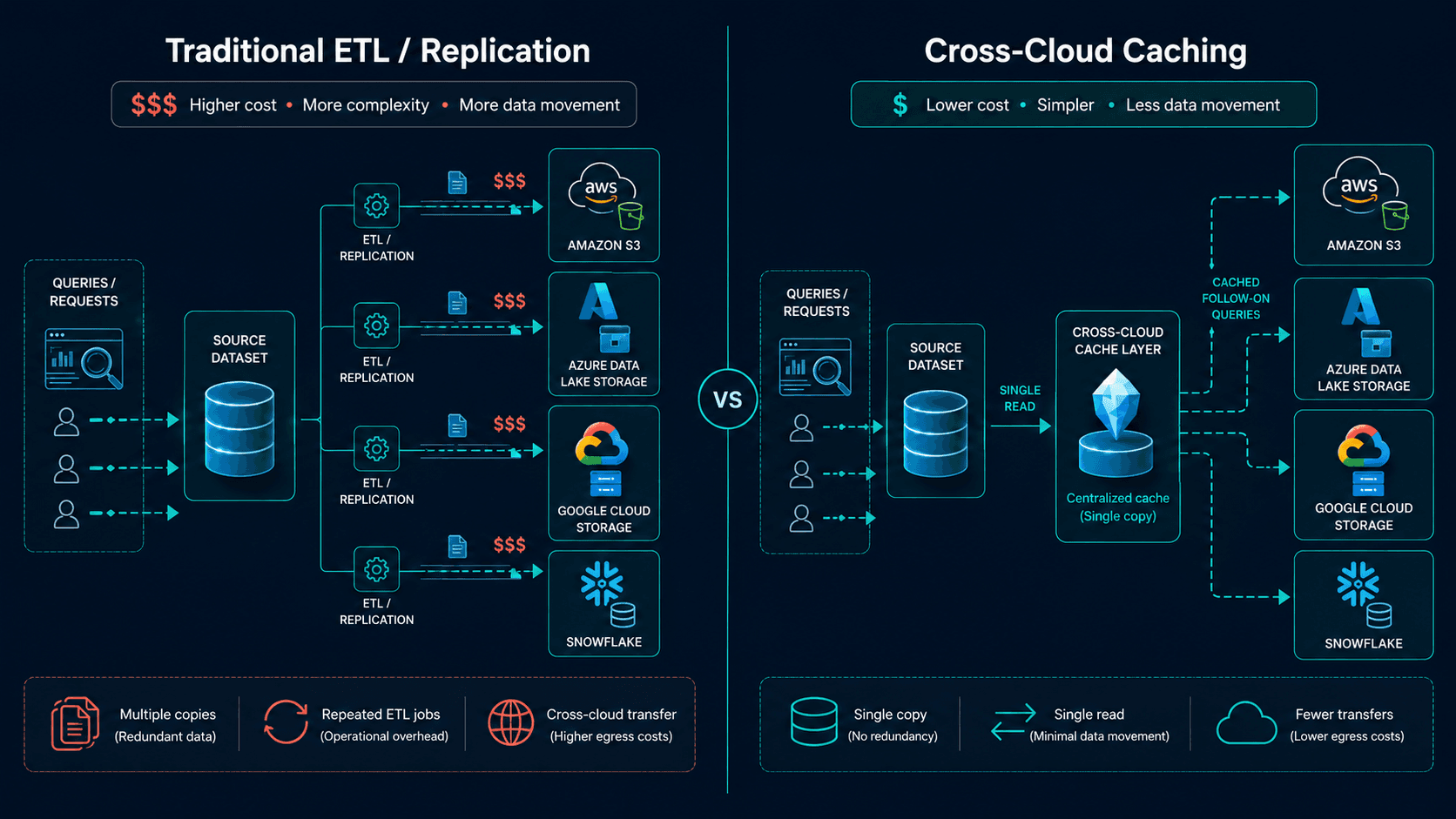
Every architect who has tried to query S3 data from a BigQuery warehouse — or Synapse data from Athena — knows the shape of the problem. You write a Glue job, or a Dataflow pipeline, or a custom Spark cluster. You replicate. You pay egress. You build monitoring for the replication. You discover schema drift the hard way. You repeat the dance every quarter when a new dataset shows up. The "multicloud strategy" deck that got signed off in 2022 turns into a permanent line item on the cloud bill, and a permanent paragraph in the SRE on-call rotation.
The honest answer most teams reached was: don't. Pick one cloud per workload, accept the lock-in, and pretend it's a feature. That worked until your data scientists wanted Vertex AI on data sitting in S3, or your finance team wanted BigQuery's pricing on data sitting in ADLS.
Three formats fought for the title — Iceberg, Delta Lake, and Hudi. As of the 2026 State of the Iceberg Ecosystem survey, 78.6% of practitioners using Iceberg use it exclusively. Iceberg v3 (now in public preview on Databricks) added Row Lineage, Deletion Vectors, and the VARIANT type for semi-structured data, which closes the last meaningful feature gaps with Delta. Every major data platform — BigQuery, Snowflake, Databricks, Redshift, Trino — now reads and writes Iceberg natively.
The reason matters. Iceberg's design separates the table metadata layer from the file storage layer in a way that lets multiple engines coordinate writes without a single vendor in the middle. That's exactly the property a cross-cloud lakehouse needs.
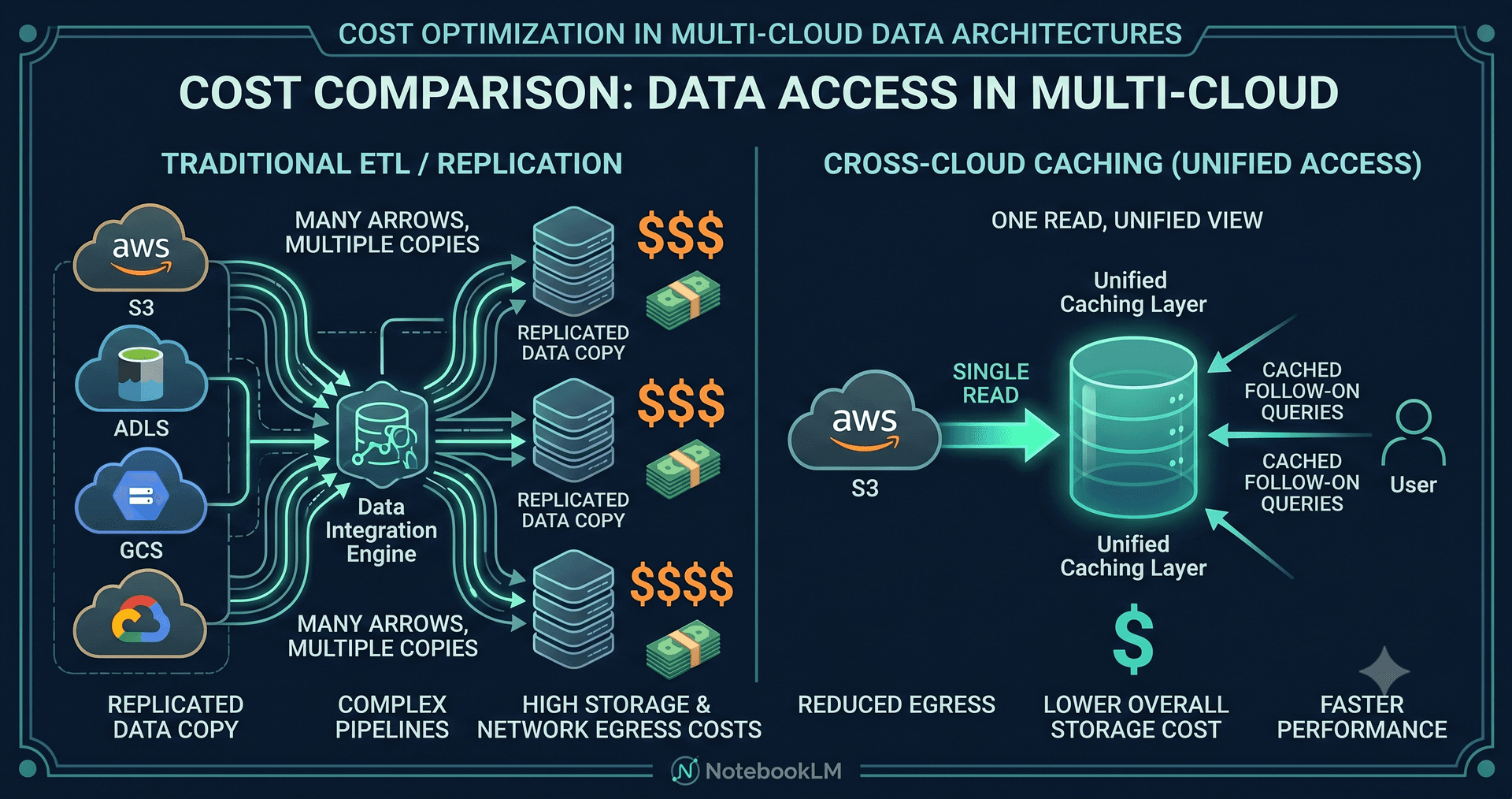
Google's Cross-Cloud Lakehouse executes BigQuery and Managed Service for Apache Spark queries directly against Iceberg tables stored in AWS S3 or Azure ADLS — no replication, no copies, no Glue jobs. The metadata catalog lives in Google Cloud, the storage stays where it was, and the query plan understands which storage backend to talk to per partition. From the analyst's seat, it's a single SQL statement against project.dataset.table. Underneath, the engine might be reading parquet files from three different clouds in the same query.
The Data Agent Kit announced at Next '26 takes the same surface and exposes it to agents — which matters because agents generate query patterns that no human would write, and they need to work across data wherever it lives.
This is the part that most coverage missed. The first read of an AWS or Azure object pulls across the cross-cloud interconnect. Every read after that hits a regional Google Cloud cache. Egress fees stop scaling linearly with query volume. For a dashboard that hits the same fact table thirty times a day, you pay egress on read one and zero on the rest.
Combined with the AWS–Google joint multicloud networking announcement — private interconnect, no public-internet hops, no per-NAT-gateway accounting — the finance department's objection to multicloud finally has an answer that survives a procurement review.
Three concrete moves to make before Q3:
First, standardize on Iceberg for any new analytical table. The format risk is now lower than the platform risk — Delta and Hudi still ship, but Iceberg is the gravity well. If your warehouse is BigQuery and your lake is S3, you no longer need to choose.
Second, audit your replication pipelines. Anything that exists purely to satisfy "the cloud you bought first" is now negative-value infrastructure. Cross-Cloud Lakehouse plus caching is usually cheaper than the Glue job you already pay for.
Third, plan your agent layer with Iceberg as the default. Every agent platform demoed at Next '26 — Agent Studio, the Data Agent Kit, the Gemini Enterprise Agent Platform — assumed Iceberg under the hood. If you're still pinning your agent's retrieval layer to a single cloud's proprietary store, you're building tomorrow's migration.
The cheapest architecture in 2026 is the one that leaves data where it is. Iceberg made that possible. Cross-cloud caching made it economical.
If your data sits in S3 but your analytics live in BigQuery, the migration tax just got smaller — and the wrong call here gets locked in for years. Book a free 30-minute strategy call.
We'll map your replication pipelines and show you what Iceberg actually saves.
Continue exploring these related topics
AWS Interconnect and Google Cloud Location Finder signal the hyperscalers have conceded multicloud. Here is a pragmatic SaaS reference architecture.

June 30, 2026, Anthropic released Claude Sonnet 5 and pitched it as the model that finally makes cheap, reliable agents the default. The claim underneath the launch is simple: near-Opus intelligence at a Sonnet price.

GLM-5.2 is Z.ai's new flagship text model for long-horizon engineering work: 1M-token context, 128K maximum output, function calling, structured output, MCP integration, and a public model card on Hugging Face.