If you wrote a Retrieval-Augmented Generation pipeline in 2024, you almost certainly bolted on a separate vector database. If you're writing one in May 2026, you should at least ask why you wouldn't just use Postgres. PostgreSQL 19 + pgvector crossed a quiet threshold this month, and the standalone vector store category is starting to look more like a feature than a market. Three things landed in April: feature freeze for PostgreSQL 19 (April 8) with stronger native vector support, AlloyDB's columnar engine moving into Preview as a read-optimized cache for HNSW indexes, and Devart's dotConnect for PostgreSQL shipping AI Vector Types in EF Core 10. Add pgvectorscale's billion-scale capabilities and the math gets uncomfortable for the standalone vendors.
The April 8 freeze that quietly changes the RAG stack
Feature freezes don't make the front page, but this one matters. PostgreSQL 19 enters beta in May with stronger vector search support landing alongside improved partitioning, logical replication, monitoring, and pg_dump improvements. The September release will be the first major Postgres version where "I just want to store embeddings here" is a first-class answer rather than an extension.
The trend behind it is bigger than one release. As VentureBeat noted in its 2026 data predictions, vectors have moved from being a database category to a data type. Postgres, Oracle, MongoDB, and SQL Server now ship native vector support. The "you need a vector DB" pitch from 2024 quietly became "you need an embedding column."
What's actually landing in PostgreSQL 19
Three pieces matter for AI workloads. First, deeper integration of vector types so that distance operators (<->, <=>, <#>) can be planned and indexed without extension-specific edge cases. Second, partitioning improvements that let you shard a large embeddings table by tenant or by time without breaking HNSW index maintenance. Third, replication enhancements that make read replicas of an embedding-heavy table actually fast — historically a pain point because vector indexes don't replicate cheaply.
None of this is revolutionary on its own. The compounding effect is that "use Postgres" stops requiring caveats for vector workloads in the 10–500 million row range, which is where the vast majority of production RAG systems actually live.
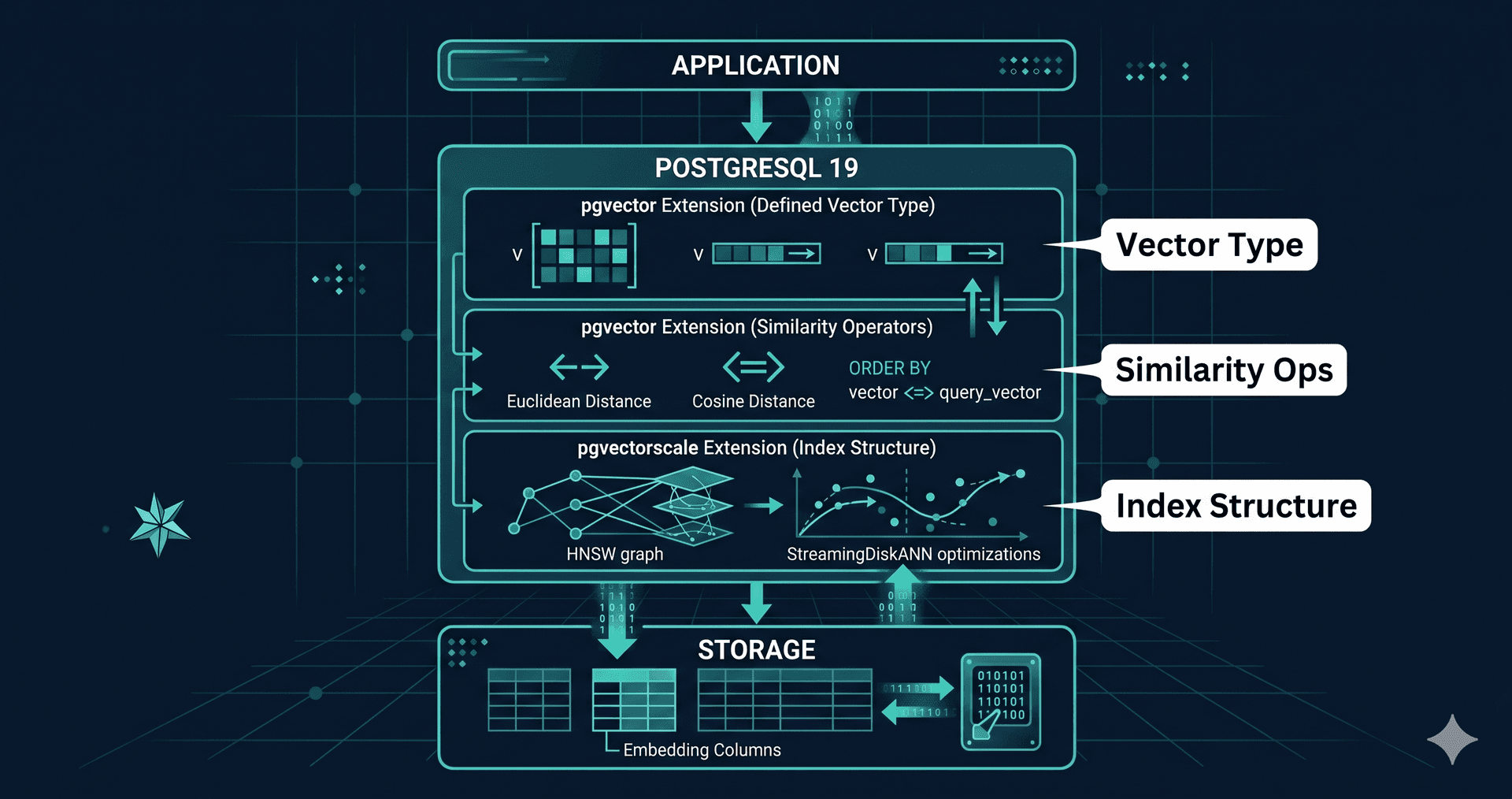
pgvectorscale and the AlloyDB columnar trick
Two extensions push Postgres past the "good enough" line. pgvectorscale adds StreamingDiskANN — an index structure designed for billion-scale vector search on a single Postgres node, with materially better recall and latency than vanilla HNSW at the same memory footprint. For teams that hit the wall on pgvector around 100M vectors, pgvectorscale extends the runway by roughly an order of magnitude.
Google Cloud's AlloyDB went further. Its columnar engine, originally an analytics accelerator, can now act as a read-optimized in-memory cache for HNSW indexes. Vector queries-per-second go up without the embedding store going wider. This is the sort of operational boring-ness that quietly puts purpose-built vector engines under cost pressure: same Postgres you already operate, more vectors, more QPS, no second cluster.
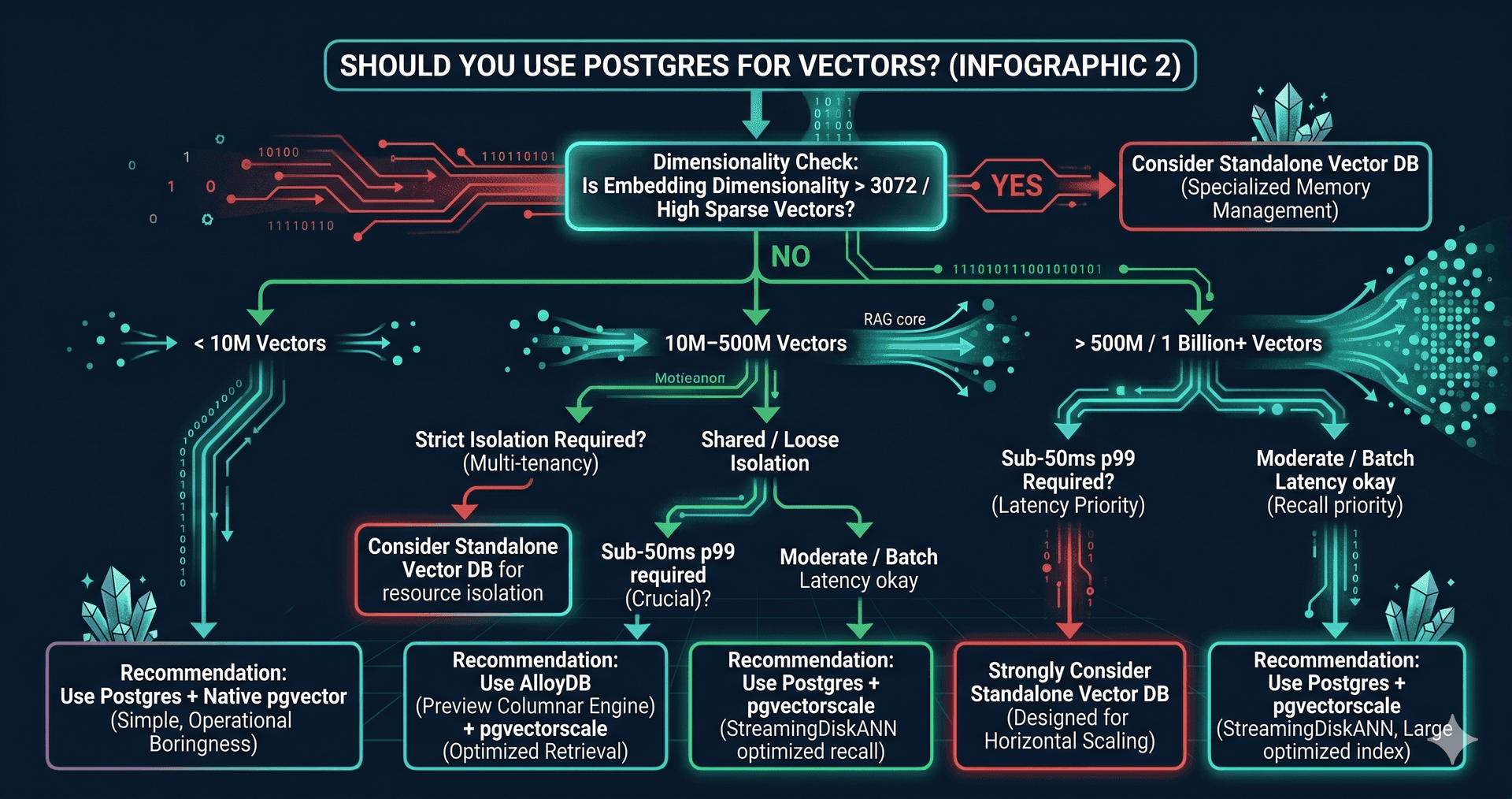
When standalone vector DBs still win
Postgres is not the right answer for every shape of vector workload. Four conditions still tilt the build toward dedicated infrastructure.
Very high embedding dimensionality — anything above 3072 dimensions — starts to stress HNSW index memory in a way that purpose-built engines handle more gracefully. Datasets above one billion vectors with sub-50ms p99 latency usually need horizontally sharded vector engines designed for that scale. Multi-tenant isolation where each tenant needs strict resource separation can be cheaper to enforce in a vector-native engine. And workloads where the embedding lifecycle is fundamentally separate from the rest of your data — pure model inference caches, for example — don't gain much from being inside Postgres.
Outside those cases, the renewal economics are increasingly unfavourable to standalone vendors. Standalone vector DBs charge for storage, compute, and index memory separately. Postgres + pgvectorscale shares your existing Aurora or RDS or AlloyDB instance. For 10–500M vectors, the savings typically run 5–10x.
A 60-day migration plan from Pinecone to Postgres
For teams staring at a six-figure renewal, here's a tested sequence. Days 1–10: stand up pgvector on a non-production replica and dual-write embeddings from your existing pipeline. Days 11–25: add pgvectorscale, build the StreamingDiskANN index, and benchmark recall and latency against your standalone vendor at production query volume. Days 26–40: shadow-route 10% of read traffic to Postgres and compare top-k overlap and latency p99 against your existing system. Days 41–55: cut over reads, leaving the standalone vendor as a fallback. Days 56–60: turn off dual-writes and confirm cost savings on the next billing cycle.
The interesting work in RAG has moved up the stack — to retrieval quality, eval harnesses, hybrid search, and re-ranking. The vector store is becoming infrastructure, and infrastructure tends to consolidate into the database you already run.




