Claude Fable 5: Anthropic's Most Powerful Model Is Here
•10 min read
Claude Fable 5 is Anthropic's first public Mythos-class model: frontier coding, a 1M-token context, and agents that run for hours. Here's what builders need to know.
On June 9, 2026, Anthropic released Claude Fable 5, its first publicly available "Mythos-class" model, just days after warning that frontier AI was getting too capable to release without new guardrails (Anthropic, Claude Fable 5 and Claude Mythos 5, June 2026). Fable 5 is the version of that frontier model Anthropic deemed safe enough to ship broadly. If you build with the Claude API, this changes your ceiling on long-running agents and coding work, but it also changes how you handle refusals, pricing, and data retention. Here's what actually matters in your code.
Key Takeaways
In June 2026, Claude Fable 5 shipped at $10 per million input tokens and $50 per million output tokens, roughly 2x Claude Opus 4.8 (Anthropic, 2026).
Anthropic calls it state-of-the-art on nearly all tested benchmarks, including the top score on Cognition's FrontierBench coding eval (Anthropic, 2026).
New safeguards fall back to Opus 4.8 in fewer than 5% of sessions, covering cyber, biology, and chemistry queries.
Builders must enable mandatory 30-day data retention before the model will run. There's no zero-data-retention option.
What Exactly Is a "Mythos-Class" Model?
A Mythos-class model is Anthropic's internal tier for its most capable frontier system, and Fable 5 is the first version released to the public. As of June 2026, Anthropic describes Fable 5 as "state-of-the-art on nearly all tested benchmarks," exceeding any model the company had previously made generally available (Anthropic, Claude Fable 5 and Claude Mythos 5, June 2026). The naming matters: Fable and Mythos are the same underlying model.
The difference is the safety envelope. Mythos 5 runs with some safeguards lifted, available only to a small set of cyberdefenders and biology researchers through a program called Project Glasswing. Fable 5 is that same model with classifiers bolted on. Think of it as one engine, two ignition keys, and you're only getting the consumer-grade key.
In June 2026, Anthropic released Claude Fable 5 as the public, safeguarded version of its Mythos-class frontier model, sharing identical weights with the restricted Claude Mythos 5 but routing high-risk queries to a fallback model (Anthropic, Claude Fable 5 and Claude Mythos 5, June 2026). For builders, this means you get frontier capability with a hard ceiling on a narrow band of restricted topics.
How Good Is Claude Fable 5 at Coding?
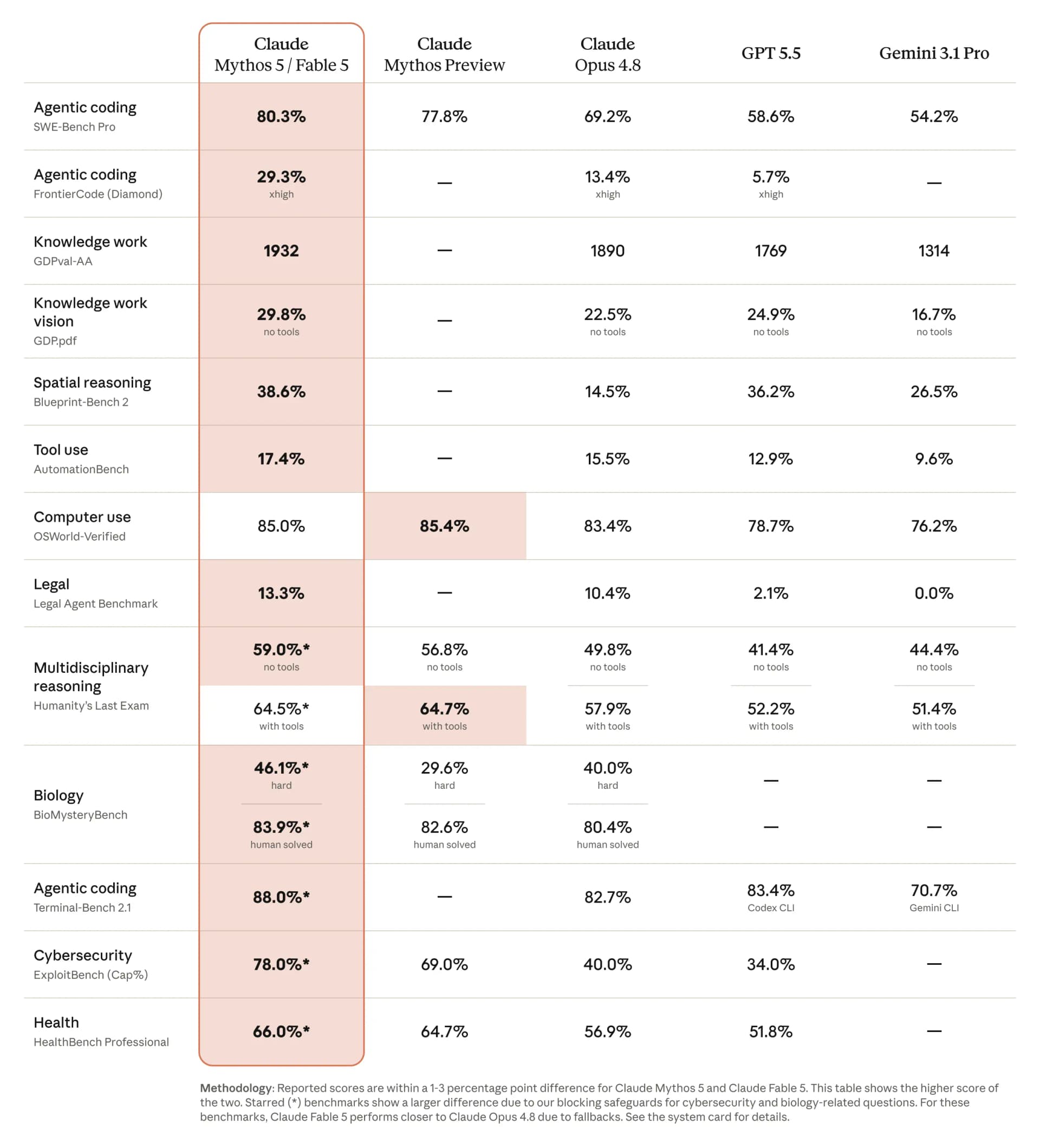
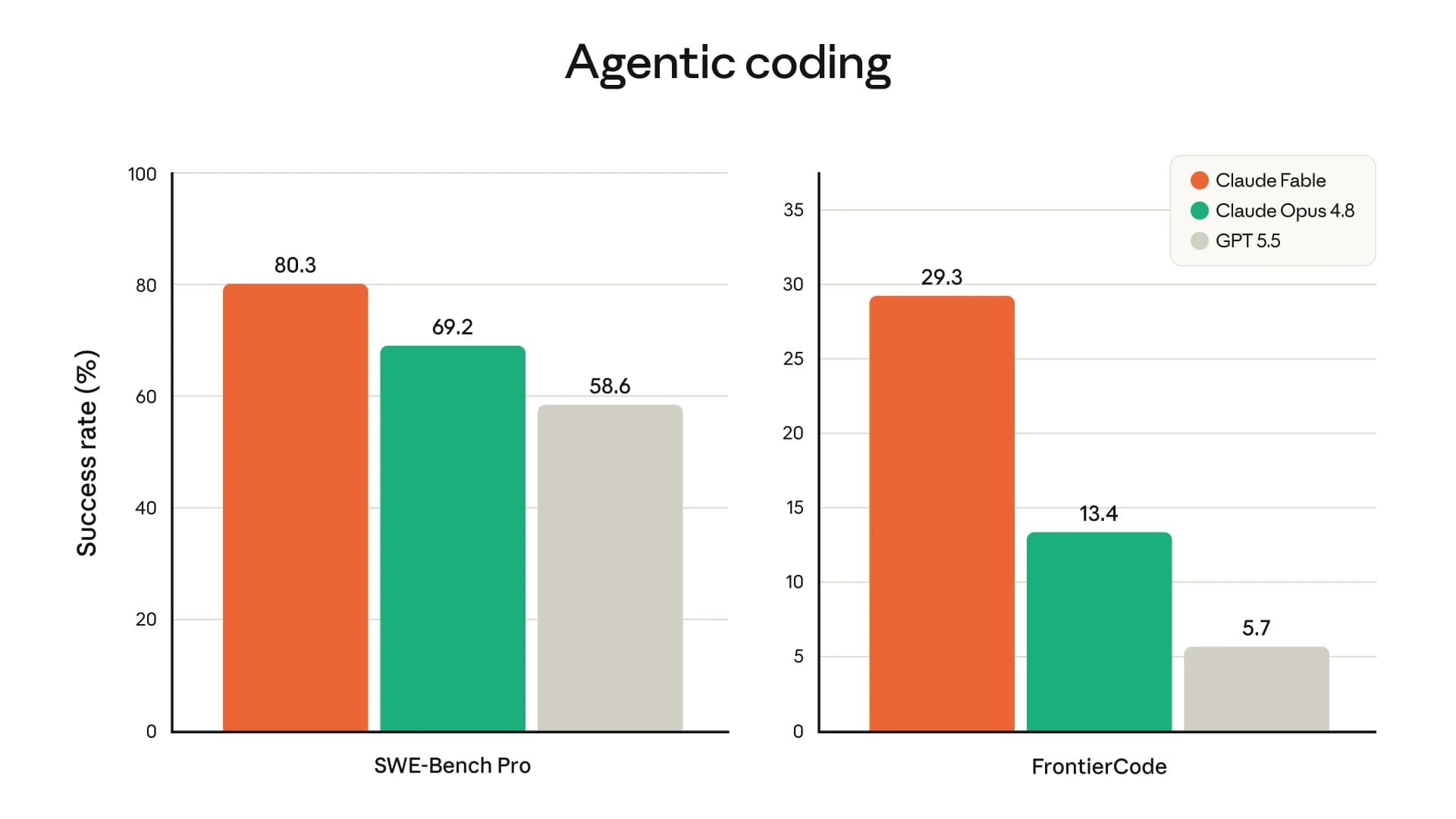
On coding, Anthropic positions Fable 5 as its strongest model yet, though it reports the results in words rather than a public numbers table. As of June 2026, Anthropic calls Fable 5 "state-of-the-art on nearly all tested benchmarks" and the "highest-scoring model on FrontierBench," Cognition's frontier coding eval (Anthropic, Claude Fable 5 and Claude Mythos 5, June 2026). The company shows a comparison chart, but it doesn't state the per-model percentages in text.
That distinction matters if you plan to cite numbers. The precise figures circulating online (a reported 95% on SWE-bench Verified, for instance) come from third parties transcribing Anthropic's published chart image, not an official text release (Kingy AI, Claude Fable 5 Benchmarks Explained, June 2026). Treat any exact percentage as a transcription until Anthropic posts a machine-readable table. What the company states plainly is where Fable leads: the hardest, longest coding tasks.
Source: Anthropic, 2026. Official claims, stated without published per-model percentages.
Anthropic also points to a real-world signal: Stripe reportedly used the model to compress "months of engineering into days" on a 50-million-line Ruby codebase (Anthropic, 2026).
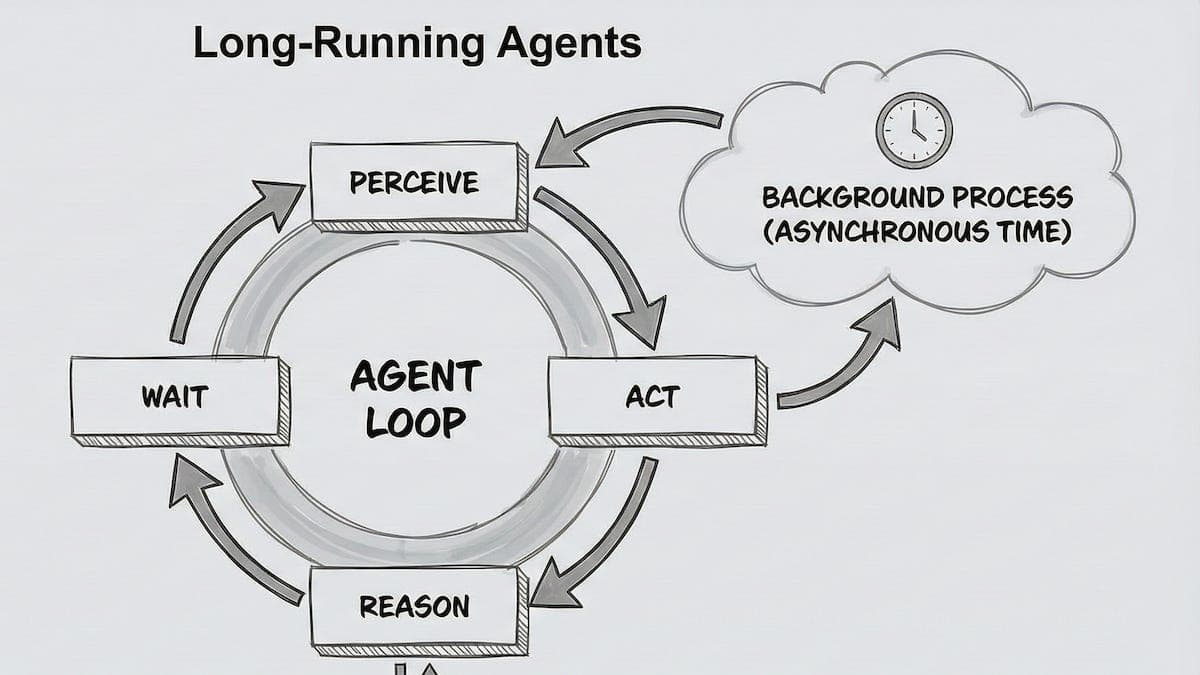
What Makes Fable 5 Different for Long-Running Agents?
The headline capability isn't a benchmark; it's endurance. As of June 2026, Anthropic and AWS both describe Fable 5 as sustaining "long-running, asynchronous execution" of coding and knowledge-work tasks that previous models could not maintain, running for hours and in some cases days without intervention (AWS, Claude Fable 5 on AWS, June 2026). Anthropic publishes no specific hour count, so don't quote one.
Two behaviors drive that stamina. The model self-verifies its own work, and with the memory tool enabled it carries context across a long session. In one test, persistent memory let it reach the final act of the game Slay the Spire three times more often than Opus 4.8 (Anthropic, 2026). Games are a proxy, sure, but the underlying skill, holding a plan across thousands of steps, is exactly what an overnight refactor needs.
Our read: The jump from "minutes of autonomy" to "hours, even days" is a bigger deal than the coding score. A model that holds a coherent plan across a long horizon changes what you can hand off unattended, from a single function to a whole migration. Adaptive thinking is always on in Fable 5, so this depth comes by default; you tune cost with the effort parameter, not a thinking on/off switch.
There's a caveat worth pricing in. A model that runs for hours bills for hours. At $50 per million output tokens, an unattended agent that loops can get expensive fast, so budget caps and the beta task-budget controls aren't optional; they're how you sleep at night.
How Do the Safeguards and Fallback Actually Work?
Fable 5 ships safe for general use because Anthropic added classifiers that route risky queries away from the frontier model. As of June 2026, those safeguards trigger on average in fewer than 5% of sessions, meaning more than 95% of Fable traffic is served by the full model with no fallback (Anthropic, Claude Fable 5 and Claude Mythos 5, June 2026). When a classifier fires on a cybersecurity, biology, or chemistry query, the request falls back to Claude Opus 4.8 instead.
Source: Anthropic, 2026 (safeguard trigger rate as reported)
For builders, the API surface is the part to read carefully. When a safety classifier declines, the Messages API returns stop_reason: "refusal" as an HTTP 200 (a successful response, not an error) and reports which classifier fired (Anthropic API docs, Introducing Claude Fable 5, June 2026). If your error handling assumes refusals throw, you'll silently mishandle them.
As of June 2026, Claude Fable 5 returns refused requests as HTTP 200 with stop_reason: "refusal", and you are not billed for a request refused before any output is generated (Anthropic API docs, June 2026). A server-side fallbacks parameter (beta) or SDK middleware lets you retry on Opus 4.8 automatically, with a credit refunding the prompt-cache cost of the switch.
Mixed-token billing follows the same logic. You pay Fable rates for tokens generated before a fallback, then Opus rates afterward, so a partly answered, partly redirected request lands on a blended bill.
What Does Claude Fable 5 Cost, and Where Can You Run It?
Fable 5 is priced at $10 per million input tokens and $50 per million output tokens, double Opus 4.8's $5/$25 but less than half the cost of the earlier Mythos Preview (Anthropic, Claude Fable 5 and Claude Mythos 5, June 2026). It carries a 1-million-token context window by default and up to 128,000 output tokens per request. The math is simple: you're paying a premium for the hardest tasks, so route easy work to a cheaper model.
Source: Anthropic, 2026
Availability is broad from day one. The model IDs are claude-fable-5 on the Claude API, anthropic.claude-fable-5 on Amazon Bedrock, and global.anthropic.claude-fable-5 for Bedrock cross-region routing (AWS, Claude Fable 5 on AWS, June 2026). It's also live on Google Vertex AI, Microsoft Foundry, and GitHub Copilot, though Copilot ships it off by default; admins must enable the Fable 5 policy.
One compliance flag before you ship: Fable 5 is a "Covered Model" with mandatory 30-day data retention for safety classification, and it isn't available under zero-data-retention. Enable data sharing via the Data Retention API first, or the call won't run. For regulated workloads, that's a conversation to have before you wire it in.
Should You Switch to Fable 5 Right Now?
For most teams, the answer is selective adoption, not a wholesale switch. Through June 22, 2026, Fable 5 is included free on Pro, Max, Team, and seat-based Enterprise plans; on June 23 it moves to usage credits (Anthropic, Claude Fable 5 and Claude Mythos 5, June 2026). That window is your free bake-off; use it to measure Fable against Opus 4.8 on your actual tasks before the meter starts.
The decision rule is cost per outcome, not benchmark rank. Reserve Fable 5 for long-horizon agents, hard multi-file coding, and dense vision work where its endurance pays for the 2x price. Keep Opus 4.8 or a cheaper model as the default for routine calls, and let the fallback mechanism handle the rest. Is a few points of SWE-bench worth double the token bill on every request? For most of your traffic, no, and that's the point of routing.
Frequently Asked Questions
What is Claude Fable 5?
Claude Fable 5 is Anthropic's first publicly available "Mythos-class" model, released June 9, 2026. It shares its weights with the restricted Claude Mythos 5 but adds safety classifiers that fall back to Opus 4.8 on high-risk queries in under 5% of sessions (Anthropic, 2026).
How much does Claude Fable 5 cost?
As of June 2026, Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens, about twice Claude Opus 4.8's $5/$25 (Anthropic, 2026). It was free on Pro, Max, Team, and Enterprise plans through June 22, then moved to usage credits.
Is Claude Fable 5 better than Opus 4.8 for coding?
On Anthropic's own benchmarks, yes. As of June 2026, Anthropic calls Fable 5 the highest-scoring model on Cognition's FrontierBench coding eval and state-of-the-art on nearly all tested benchmarks, with its widest lead on the hardest multi-file tasks (Anthropic, 2026). Exact percentages circulating online are third-party transcriptions of Anthropic's chart, so validate on your own codebase.
What is the Claude Fable 5 API model ID?
The model ID is claude-fable-5 on the Claude API, anthropic.claude-fable-5 on Amazon Bedrock, and global.anthropic.claude-fable-5 for Bedrock cross-region routing (AWS, 2026). It's also on Google Vertex AI, Microsoft Foundry, and GitHub Copilot.
What's the difference between Claude Fable 5 and Mythos 5?
They're the same underlying model. Mythos 5 runs with some safeguards lifted and is restricted to a small group of cyberdefenders and biology researchers via Project Glasswing, while Fable 5 is the public version with classifiers that block and reroute high-risk queries (Anthropic, 2026).
Conclusion
Claude Fable 5 raises the ceiling on what you can hand an AI unattended: frontier coding scores, a 1M-token context, and endurance measured in hours rather than minutes. But it's a tool with a sharp edge: double the price, mandatory 30-day retention, and refusals that arrive as HTTP 200s your code must handle. Adopt it deliberately:
Use the free window through June 22, 2026 to bake Fable 5 off against Opus 4.8 on your real tasks.
Route by difficulty. Reserve Fable for long-horizon and hard coding work, default cheaper models elsewhere.
Wire up fallbacks and budgets before you ship, so refusals and runaway loops don't bite.