Let's be honest — the AI space moved so fast in 2026 that keeping up feels like a part-time job.
GPT-5.5 dropped April 23. Anthropic punched back with Claude Opus 4.8 on May 28. Five weeks apart. Both claiming to be the most capable AI model available. Both targeting the exact same users: developers, founders, and enterprises who need answers they can actually trust.
So which one actually deserves your time, your workflows, and your money?
We dug through the benchmarks, tested real-world use cases, compared the pricing, and broke it all down. No hype. No fluff. Just the stuff you actually need to decide.
Quick Overview
Claude Opus 4.8 is Anthropic's third Opus 4 release in under two months, which says a lot about Anthropic's current pace. The story here isn't raw horsepower. It's honesty and engineering depth. This model catches its own mistakes, flags uncertainty before you walk into a wall, and leads every publicly available model on real-world software engineering benchmarks. Same price as last month. Better model.
GPT-5.5 is OpenAI's biggest release since GPT-4.5, fully rebuilt from scratch, natively omnimodal, and already the default ChatGPT experience for tens of millions of users as of May 5th. OpenAI positions it as "a new class of intelligence built for real work." The benchmarks on web tasks and terminal automation back that up. The price hike, though? That's a different conversation.
Benchmarks: Where Each Model Actually Wins
Numbers tell part of the story. Here's what the data actually shows.
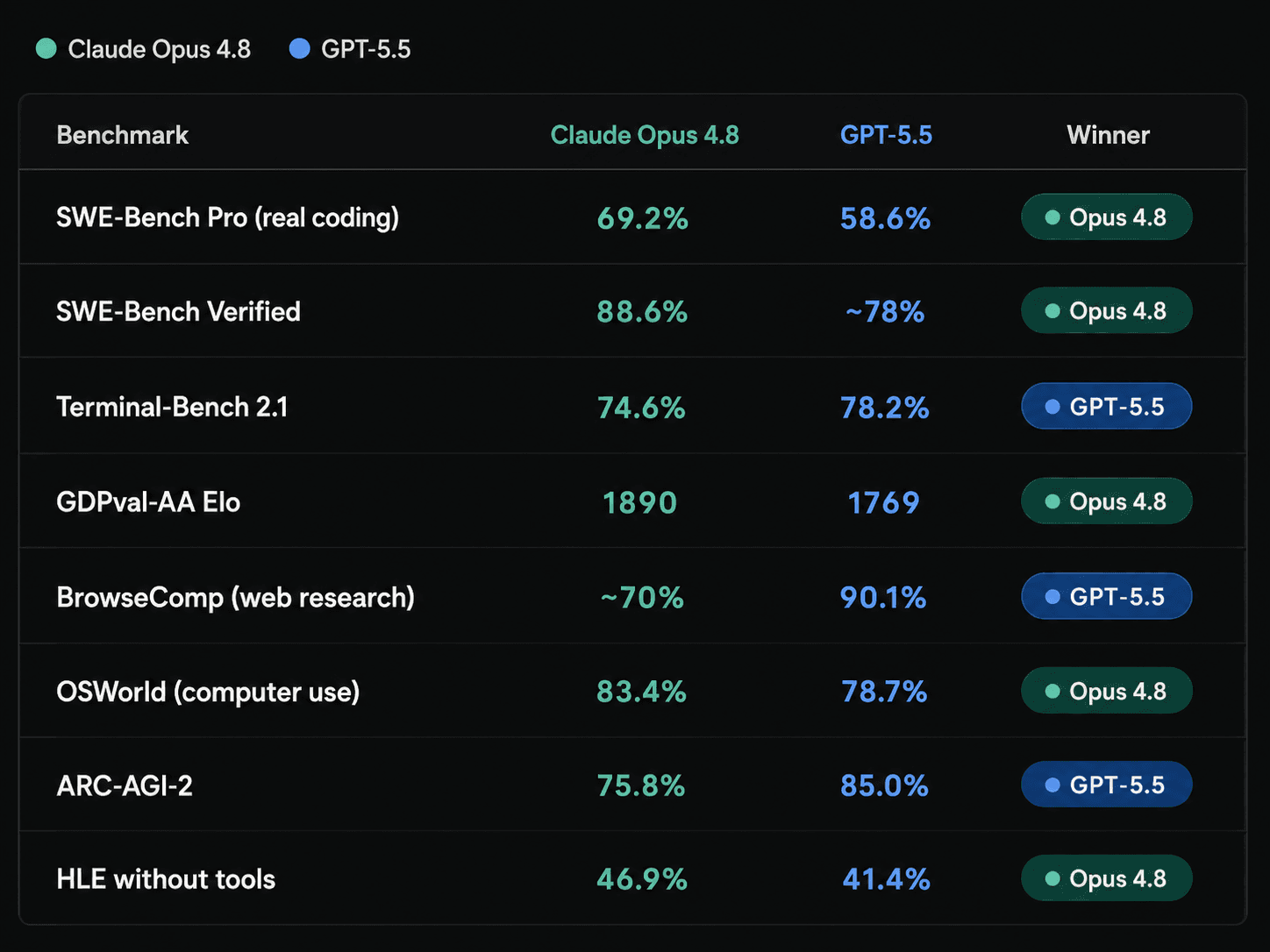
Opus 4.8 dominates software engineering. GPT-5.5 leads on web tasks, terminal work, and advanced reasoning. Neither model wins everything, and anyone pretending otherwise is selling something.
Coding & Software Engineering
This is where the gap is the widest, and where it matters the most.
Opus 4.8 scores 69.2% on SWE-Bench Pro. GPT-5.5 scores 58.6%. That 10.6-point lead isn't a rounding error. It's the difference between a model that finishes a codebase migration and one that stalls halfway through.
What makes Opus 4.8 genuinely different here isn't just the score. It's the behavior. Older models had a bad habit of saying "done!" when the work was nowhere close to finished. Opus 4.8 flags what it's uncertain about, catches its own bugs before you do, and pushes back when your plan has a hole in it. Anthropic measured it as 4x less likely than Opus 4.7 to let code flaws pass through unnoticed.
For engineers and development teams, this is the clearest win on the board.
Web Research & Agentic Tasks
GPT-5.5 was built for agents, and it shows.
The BrowseComp score of 90.1% is not a close race. For any workflow that involves navigating the live web, scraping competitive intelligence, running multi-step research across dozens of sources, or coordinating complex tool chains, GPT-5.5 operates at a level nothing else publicly available can match.
The natively omnimodal architecture is also worth highlighting. Text, images, and code aren't three separate systems patched together. They're one. When GPT-5.5 switches from analyzing an image to writing code to searching the web, it doesn't lose context. Earlier models fumbled that transition constantly.
For research-heavy workflows and live-web agentic tasks, GPT-5.5 is the right call.
Pricing: The Part That Actually Stings
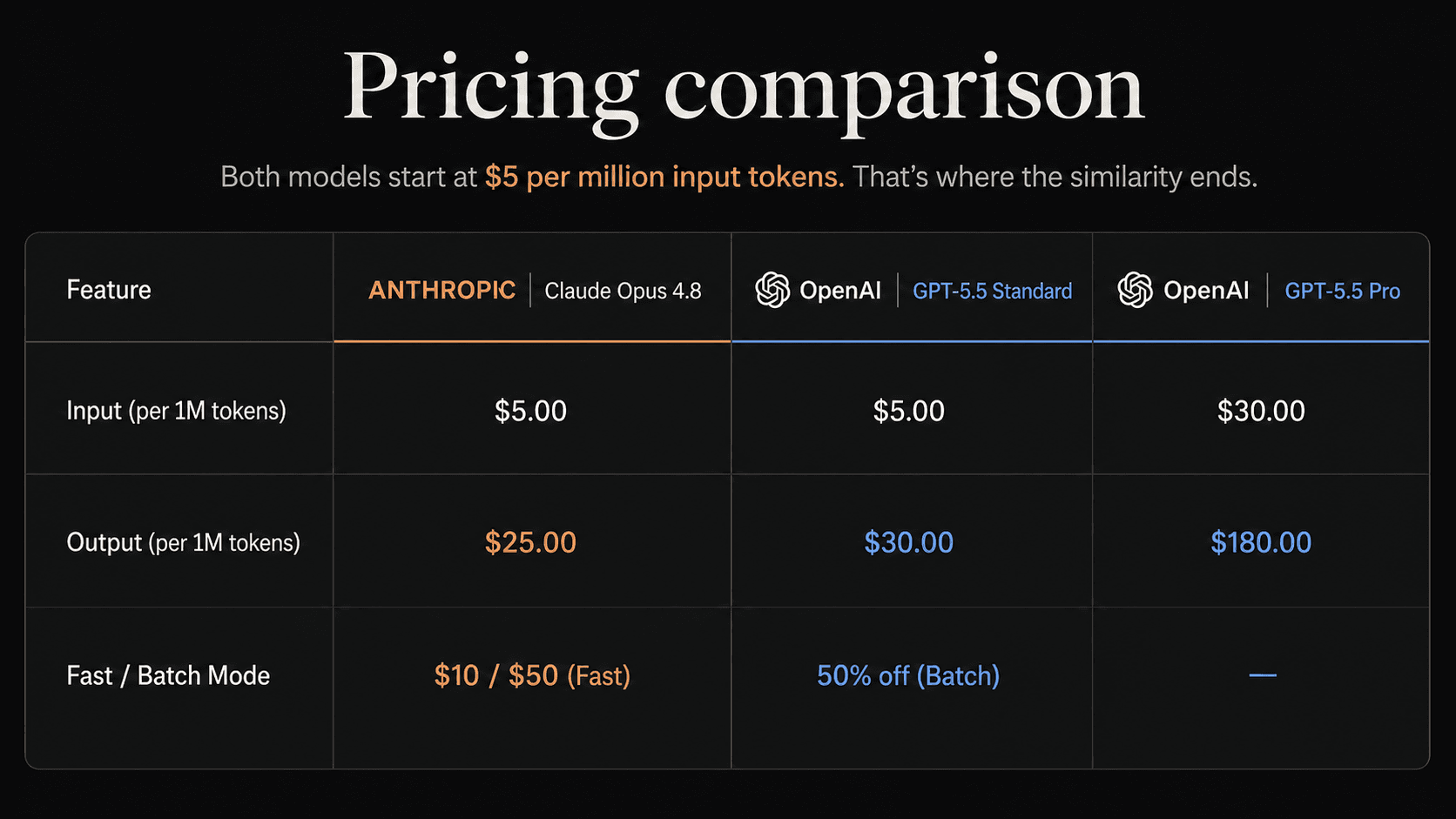
The 20% output gap between Opus 4.8 and GPT-5.5 standard compounds fast. At 10M output tokens per month, a reasonable production workload, you're looking at $250 vs $300. At 100M tokens, that's $2,500 vs $3,000.
Here's what OpenAI didn't make a lot of noise about: GPT-5.5 doubled in price from GPT-5.4. Opus 4.8 kept the exact same rate as Opus 4.7. Better model, same bill.
The GPT-5.5 Pro tier at $180/M output tokens is a different product entirely, built for tasks where a wrong answer costs more than the compute. Legal review, financial analysis, high-stakes research. Not a default for most teams.
What's New in Each Model
Claude Opus 4.8
Effort Control is the feature that doesn't get enough attention. There's now a dial right next to the model picker that lets you tell Claude how hard to think. Turn it up for complex, messy problems. Turn it down when you need fast answers without burning through rate limits. Opus 4.7 never gave you that control.
Dynamic Workflows in Claude Code let Opus 4.8 plan a big task, spin up hundreds of parallel subagents to attack it simultaneously, and self-verify before the result lands on your screen. Codebase migrations that used to grind through an entire session now run start to finish in one go. Still in research preview, but the direction is clear.
Honesty upgrades are real. The misalignment score dropped from 2.5 to 1.9, nearly matching Anthropic's unreleased Mythos model. It lies to you less. Which, honestly, is the upgrade most people needed.
GPT-5.5
Persistent Memory is the biggest quality-of-life improvement. GPT-5.5 now pulls context from your past conversations, uploaded files, and connected services like Gmail. After a few weeks, it starts to feel less like a tool and more like something that actually knows your preferences, your formats, and your projects.
Omnimodal Architecture means text, images, code, and tool use are woven into a single system rather than bolted together. Workflows that require all three modalities feel genuinely smooth, not like switching between three different modes.
Hallucination Reduction: OpenAI claims a 50%+ drop on high-stakes topics, concentrated in medicine and law. Developer sentiment broadly aligns with the claim, though independent corroboration is still catching up.
Pros and Cons
Claude Opus 4.8
What works well:
Best-in-class software engineering scores. Honest about its own limits. Effort control dial gives real cost leverage. Holds context and voice across long sessions without drifting. Same price as last month. Fast Mode now 3x cheaper than the previous fast tier.
What needs work:
Dynamic workflows are still in research preview, not production-ready. Context window capped at 200K on Microsoft Foundry while running 1M everywhere else. Most expensive model by output rate when comparing across the full competitive landscape.
GPT-5.5
What works well:
Best web research and browsing performance of any publicly available model. Strong terminal and DevOps automation. Persistent memory that compounds over weeks of use. Tight GitHub Copilot and Codex integration. Improved hallucination resistance in high-stakes domains.
What needs work:
Output tokens cost 20% more than Opus 4.8. Mid-session memory is inconsistent and can forget its own earlier outputs in long conversations. Model routing is still unpredictable in production pipelines. Doubled in price from GPT-5.4 with limited public announcement.
User Experience: What It Actually Feels Like Day to Day
On Claude.ai, Opus 4.8 feels noticeably cleaner than its predecessor. The over-verbose code comments that drove engineers up the wall in 4.7? Gone. It asks sharper clarifying questions before jumping in. The effort dial is right there when you need it. On long complex sessions it holds the thread, something that used to fall apart around message twenty.
On ChatGPT, GPT-5.5 feels more like a personal assistant that's been watching you work. The memory integration creates a different kind of relationship. It knows your workflow, your preferred formats, the projects you keep coming back to. The interface is more polished for everyday conversation. Less like a technical tool, more like a capable generalist you've trained over time.
Both have mobile apps, desktop clients, and voice support. The real difference is in what you're building: Claude is the focused collaborator for hard technical work, ChatGPT is the personalized generalist for everything else.
Who Should Use What
Choose Claude Opus 4.8 if you're building and maintaining software, running Claude Code workflows, working on long-context documents, or need a model that will be honest about what it actually completed. It's cheaper at scale, more transparent about its limits, and leads the field on the engineering benchmarks that reflect real work.
Choose GPT-5.5 if web research, live-web agentic tasks, or terminal automation are the core of your work. Or if you're already deep in the OpenAI and Microsoft ecosystem where switching costs are real. Or if persistent memory that learns your preferences over time matters to your daily workflow.
Use both if you're serious about production. Route Opus 4.8 to engineering depth and long-context work. Route GPT-5.5 when the job touches the live web or requires strong terminal automation. The teams getting the most out of 2026's frontier models aren't loyal to one. They're thoughtful about which one they call.
The Bottom Line
Five weeks apart. Two fundamentally different bets on what makes an AI worth paying for.
Opus 4.8 is quieter about its improvements but more consistent in the places that actually count. Same price, better judgment, and a model that tells you the truth instead of the answer you were hoping for.
GPT-5.5 is a genuinely new kind of model, rebuilt from scratch, built for agents, and the strongest thing OpenAI has ever shipped for web-heavy workflows. But it's pricier, occasionally forgetful mid-session, and loses to Opus 4.8 on the coding benchmarks that define most real development work.
Neither is the final word. Anthropic has Mythos reportedly weeks out. OpenAI's release cadence is now measured in weeks, not quarters. The race is far from over, but right now in May 2026, these are the two models setting the pace.
References