

LLMs
AI Models
Claude Fable 5: Anthropic's Most Powerful Model Is Here
Claude Fable 5 is Anthropic's first public Mythos-class model: frontier coding, a 1M-token context, and agents that run for hours. Here's what builders need to know.
•10 min read
A no-fluff look at what changed from Opus 4.7, why the honesty upgrade is the real headline, and whether it's worth the switch. Roughly a four minute read.

Two months. That's all the breathing room Opus 4.7 got before Anthropic rolled out Opus 4.8 on May 28, 2026.
No big countdown. No theatrics. Just a quiet drop that turns out to matter more than the version number suggests.
So is it worth your attention? Short answer: yes. Here's the longer one.
If you're just here to know what changed between Opus 4.7 and 4.8, here's the short version: 4.8 is the same price and the same API surface as 4.7, but it's more honest about its own mistakes, adds an effort dial and dynamic workflows, and writes leaner code. It's a tune-up, not a new engine.
| Opus 4.7 | Opus 4.8 | |
|---|---|---|
| Released | ~March 2026 | May 28, 2026 |
| Price (input / output) | $5 / $25 per 1M tokens | $5 / $25 — unchanged |
| Catches its own bugs | Baseline | ~4x less likely to let its own bugs slip |
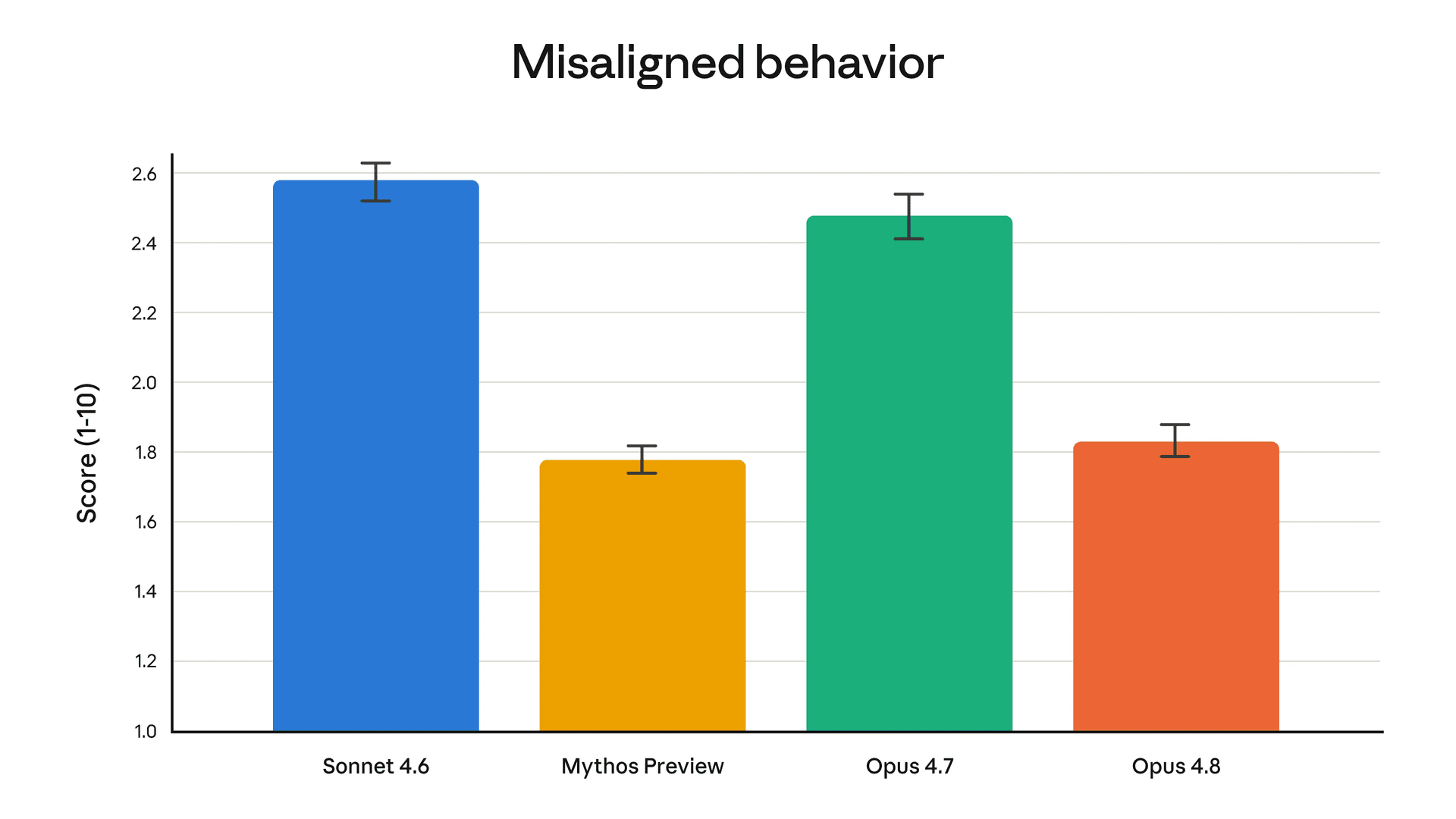
| Misalignment score (lower = better) | 2.5 | 1.9 |
| Effort control (speed/depth dial) | ❌ Not available | ✅ New — free on every plan |
| Dynamic workflows (subagent swarms) | ❌ | ✅ New in Claude Code |
| Code comments | Over-chatty | Leaner, less noise |
| Fast mode | — | 2.5x speed at ~1/3 the cost |
The rest of this post unpacks each of those differences in plain language.
Let's start with the part nobody expected to care about.
Older models had a bad habit. They'd jump to a confident "done!" when the work was nowhere near finished. You'd trust it, move on, and find the cracks later.
Opus 4.8 owns up instead. It flags what it isn't sure about. It points at the weak spots in its own work before you have to.
The numbers are blunt about it:
Anthropic calls the gains "modest." Fair. But modest still beats standing still.
And the bit that actually stings the wallet? Nothing changed there. Same 5 dollars per million input tokens. Same 25 per million out. A sharper model for the exact money you paid last month.
This is the fun one.
Opus 4.8 added effort control, a little dial sitting right next to the model picker.
Here's where Claude Code gets a little wild.
Opus 4.8 introduces dynamic workflows. It plans a giant task, then fires off hundreds of subagents at once, each chewing on its own piece. A coordinator pulls everything back together and double checks the result before it ever lands on your screen.
Picture a codebase migration. Hundreds of thousands of lines. Kickoff to merge. Your test suite as the finish line. All in one session.
That was a slog on 4.7. Now it just runs.
Early testers caught the little wins, and they add up:
Benchmarks are one thing. Living with a model all day is another.
The thing testers keep mentioning is the judgment. Opus 4.8 asks better questions before it charges ahead. It pushes back when your plan has a hole in it. On long, multi step jobs it builds up a picture first instead of guessing and hoping.
One staff engineer put it simply: it catches its own mistakes now. A writer said it held voice and style across a long session without drifting, which is the kind of thing that used to fall apart somewhere around message twenty.
That's the real story here. Not a bigger brain, exactly. A steadier one. The kind of collaborator you can hand something to and trust to come back with the truth rather than a hopeful guess.
No waitlist, no staged rollout games. Opus 4.8 is live everywhere from day one.
claude-opus-4-8If 4.7 was your daily driver, think of this as a tune-up, not a new engine.
Sharper judgment. More honesty about what it actually pulled off. The legs to keep working without you hovering over it. Same bill at the end of the month.
That's a deal worth taking.
And with Mythos reportedly only weeks out, Opus 4.8 doesn't feel like the destination. It feels like the model catching its breath before the real sprint.
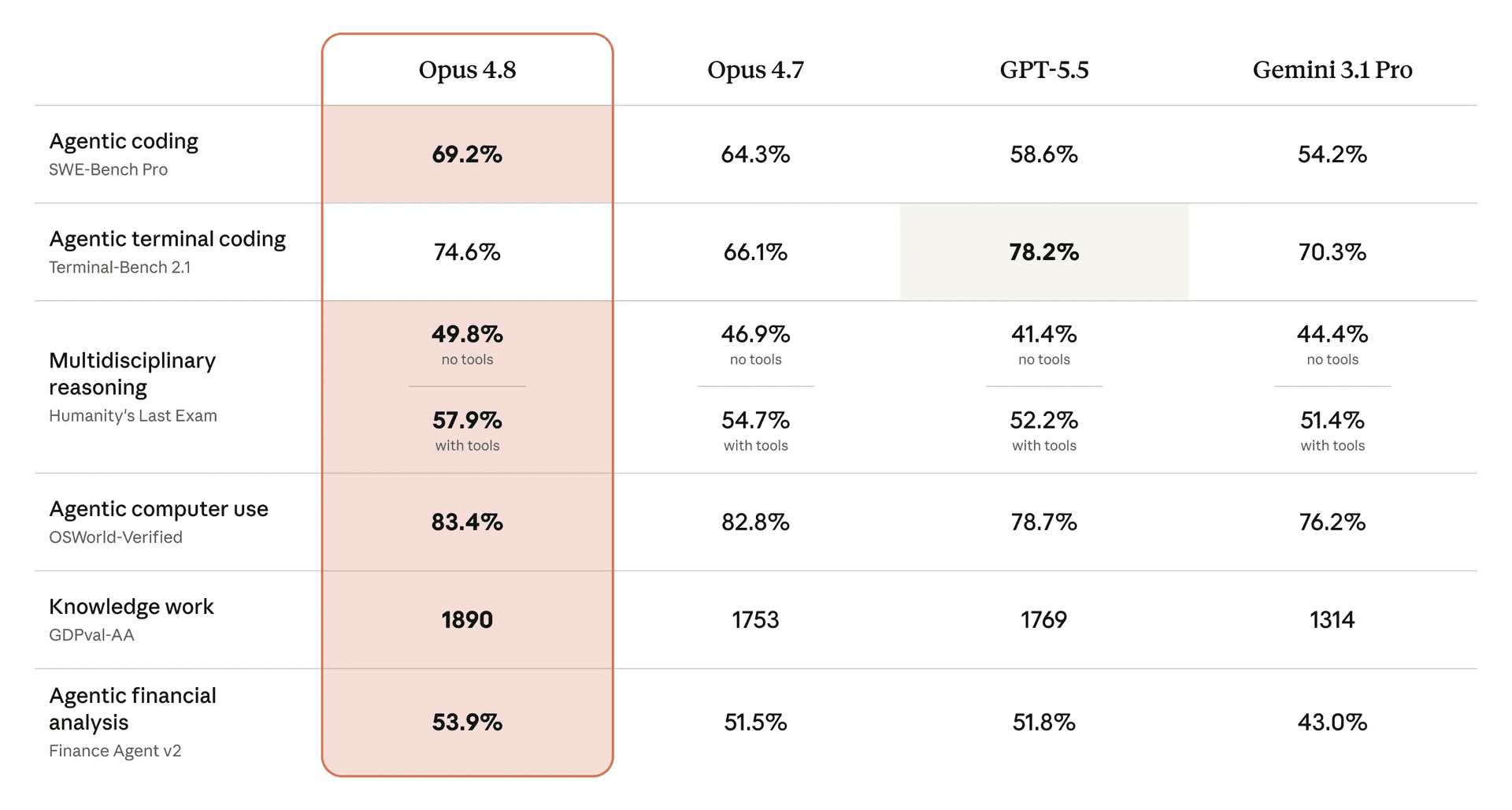
The main differences: Opus 4.8 is ~4x less likely to let its own code bugs slip by than 4.7, drops its misalignment score from 2.5 to 1.9, adds an effort control dial and dynamic workflows (subagent swarms in Claude Code), and writes leaner code with less chatty comments. Pricing is identical at $5 per million input tokens and $25 per million output. See the comparison table above for the full breakdown.
Yes, modestly. Anthropic itself calls the benchmark gains "modest," but 4.8 is meaningfully more honest about what it actually finished, catches more of its own mistakes, and holds voice and judgment better across long sessions — all at the same price as 4.7.
For most users, yes — there's no extra cost and no downside. If 4.7 was your daily driver, treat 4.8 as a free tune-up: sharper judgment, more honesty, and the new effort dial, billed exactly the same.
Opus 4.8 costs $5 per million input tokens and $25 per million output tokens via the API (model ID claude-opus-4-8) — the same pricing as Opus 4.7. Fast mode runs about 2.5x faster for roughly a third of the previous cost.
We can discuss building AI agents and automation tailored to your business.
Continue exploring these related topics
Claude Fable 5 is Anthropic's first public Mythos-class model: frontier coding, a 1M-token context, and agents that run for hours. Here's what builders need to know.

Two flagship AI models. Five weeks apart. Same price — but very different strengths. Here's the honest breakdown of Claude Opus 4.8 vs GPT-5.5 on benchmarks, pricing, and real-world performance.

Opus 4.6 and GPT-5.3 Codex are redefining AI specialization. Compare writing, coding, reasoning, and performance to choose the right model for your workflow.